
728x90
Kafka 정의
- 이벤트 스트리밍 플랫폼
Kafka 아키텍처
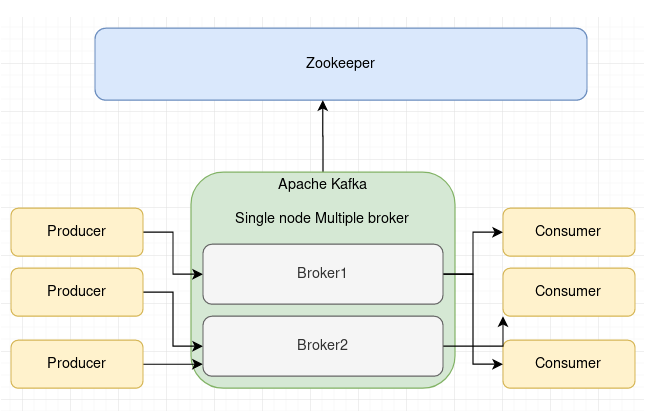
- Kafka는 발행-구독(publish-subscribe) 모델을 기반으로 동작하며 크게 프로듀서, 컨슈머, 브로커로 구성
- 프로듀서는 메세지(이벤트)를 카프카에 넣고, 브로커는 메세지(이벤트)를 저장 (브로커는 일반적으로 3대이상 구성, 클러스터 형태), 컨슈머는 메세지(이벤트)를 읽는 역할
- 주키퍼는 카프카 클러스터를 관리하는 역할, 추후에는 컨플루언트에서 주키퍼와 연동하지 않도록 구성할 예정이라고함
Kafka 구성요소
Topic / Partition / Offset
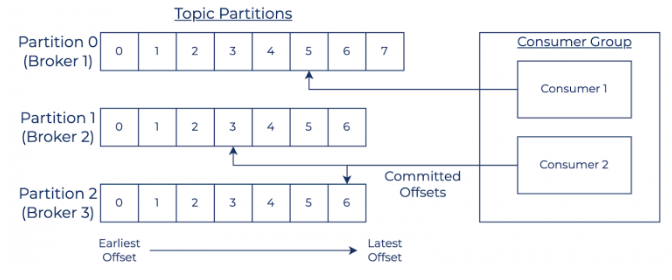
| 종류 | |
| Topic |
|
| Partition |
|
| Offset |
|
Broker
- 카프카가 설치되어있는 서버 단위, 기본 3개이상 구성 권장 (클러스터링 구성)
- 브로커에 여러개의 토픽이 존재할 수 있고, 하나의 브로커에만 설정되는 것이 아니라 여러개의 브로커에 나누어서 하나의 토픽을 생성할 수 도 있음
Producer / Consumer
| 종류 | |
| Producer |
|
| Consumer |
|
Consumer Group
- 하나의 토픽을 구독하기 위한 여러 컨슈머들의 모음
- 가용성 때문에 컨슈머를 그룹화함
Zookeeper
- 클러스터내의 서버들을 관리하는 역할 (브로커 관리)
- 클러스터 최신 설정 정보 관리 동기화, Replication 리더 채택을 함
- 브로커에 분산 처리된 메세지 큐의 정보를 관리
- 카프카 클러스터를 관리하기 때문에 카프카 서버 기동시 주키퍼가 먼저 기동되어야함
Kafka 특징
- 높은 처리량 : 프로듀서가 컨슈머로 데이터를 보낼때와 컨슈머가 브로커로 데이터를 받을때 묶어서 전송함, 묶음단위로 빠르게 처리
- 확장성 : 안정적으로 확장이 가능함, 예를 들어 데이터 요청이 많을 경우 브로커 개수를 늘려 스케일 아웃이 가능
- 영속성 : 전송받은 데이터를 메모리에 저장하지 않고 파일 시스템에 저장
- 고가용성 : 3대이상의 서버로 운영되기 때문에 서버에 장애가 발생하더라도 무중단으로 안전하게 운영이 가능
'KAFKA' 카테고리의 다른 글
| [KAFKA] 토픽 / 파티션 / 컨슈머 그룹 관계 (0) | 2025.01.31 |
|---|